Motivation and Research Question

Comparison between 360-degree panoramic image-text pairs and conventional perspective image-text pairs.
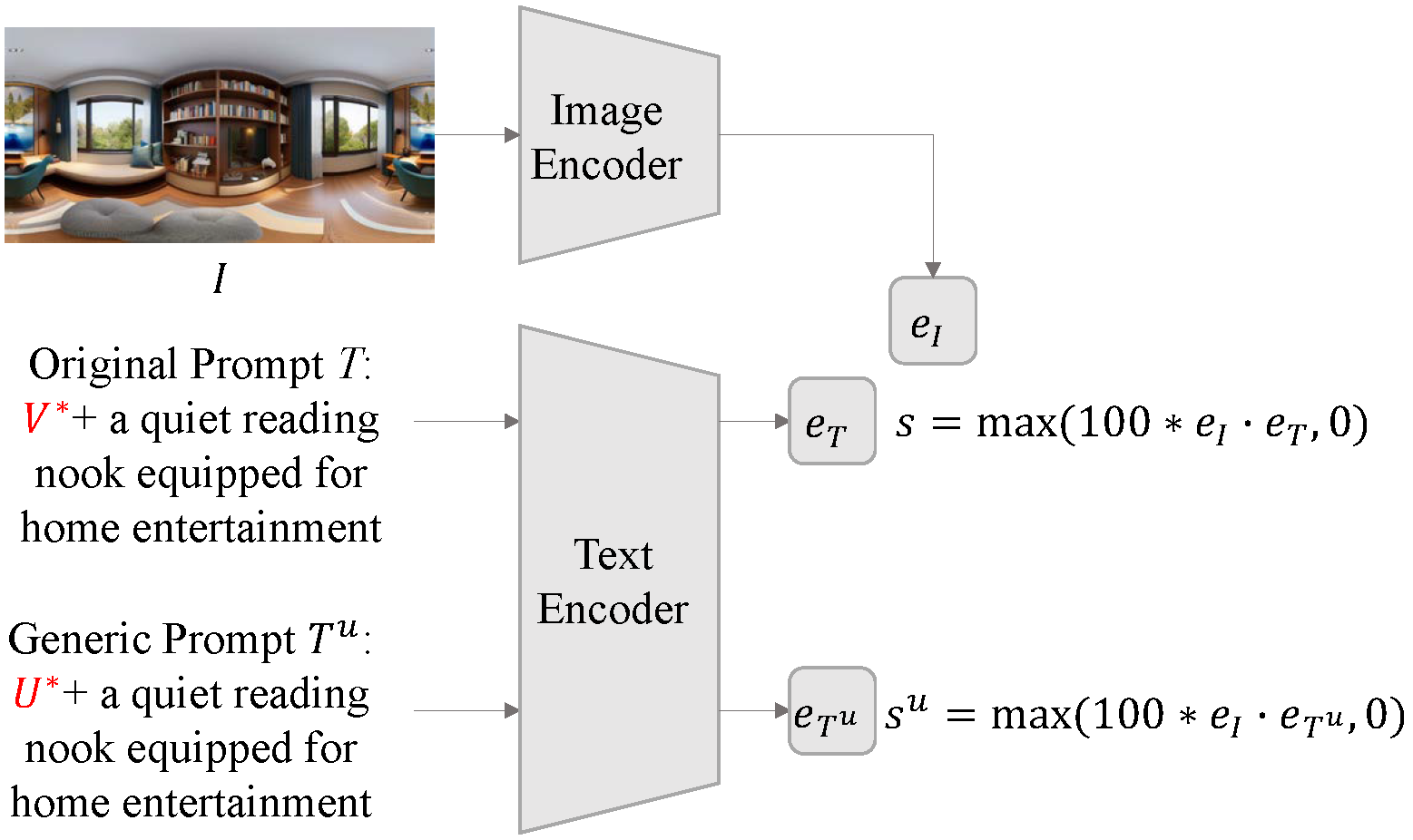
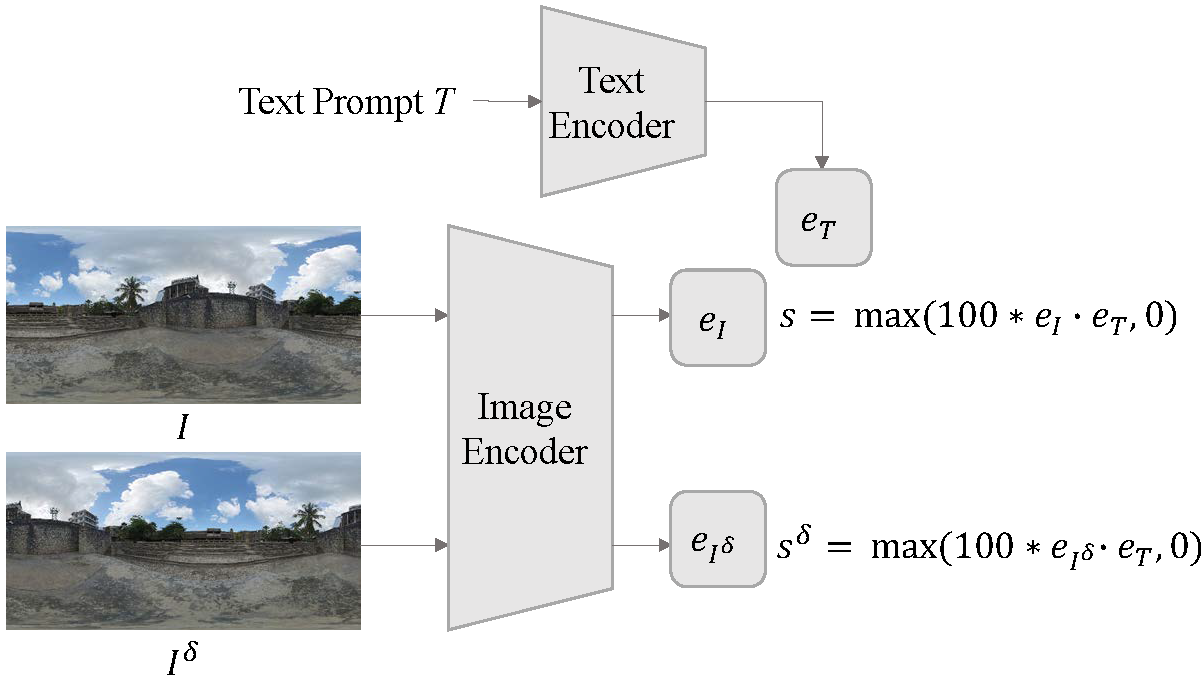
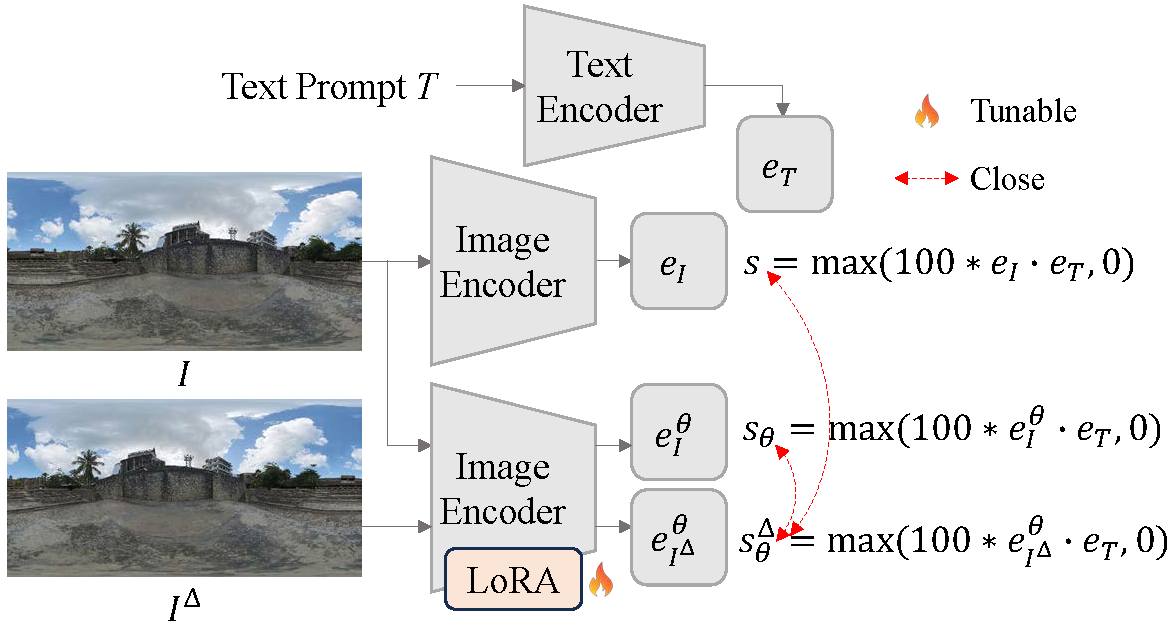
Motivation: 360-degree panoramic image-text pairs exhibit distinct semantic attributes in both textual and visual modalities, compared to perspective image-text pairs. Textually, prompts for 360-degree panoramic images often include explicit 360-degree panoramic format identifiers such as “a 360 degree view of” or “360 photo”, which convey what we define as 360-degree textual semantics. Visually, 360-degree panoramic images capture a complete spherical field of view (360° × 180°), which results in inherent semantic invariance under horizontal circular shifts; the scene content remains identical despite rotation. We term this invariant semantics 360-degree visual semantics.
Research Question: To what extent can standard CLIP models, predominantly trained on perspective image-text pairs, comprehend the distinct semantics inherent in 360-degree panoramic image-text pairs?